
Kurze Antwort (Schnelle Übersicht für eilige Leser)
Unicode ist ein weltweiter Standard, der jedem Zeichen auf der Welt — ob Buchstabe, Zahl, Sonderzeichen oder Emoji — eine eindeutige Nummer zuweist. Eine Schriftart (Font) entscheidet dann nur, wie dieses Zeichen visuell auf dem Bildschirm aussieht. Beide zusammen sorgen dafür, dass Text auf jedem Computer, Smartphone und Betriebssystem korrekt angezeigt wird — egal welche Sprache, egal welches Gerät.
Was ist Unicode? – Die einfache Erklärung
Stell dir vor, du schickst einen Brief an jemanden in Japan. Du schreibst ihn auf Deutsch, aber dein Briefpartner hat eine völlig andere Schreibmaschine, die deinen Text nicht lesen kann. Genau das war das Problem der frühen Computerwelt — und genau dieses Problem hat Unicode gelöst.
Bevor Unicode existierte, hatte jedes Land und jedes System seine eigene Tabelle dafür, welche Zahl welchem Zeichen entspricht. In einem System war „A“ die Zahl 65. In einem anderen war es 193. Wenn diese Systeme miteinander kommunizierten, wurde aus deinem schön geschriebenen Text unlesbares Zeichendurcheinander.
Unicode kam in den frühen 1990ern als Antwort auf dieses Chaos. Das Ziel war simpel, aber riesig: Ein einziger Standard für alle Zeichen der Welt. Jedes Zeichen bekommt eine einmalige Nummer — und diese Nummer gilt überall, auf jedem Gerät, in jedem Land.
Heute deckt Unicode über 140.000 Zeichen ab. Dazu gehören lateinische Buchstaben, kyrillische Schrift, arabische Zeichen, chinesische Schriftzeichen, Emojis, mathematische Symbole, Pfeile, Währungszeichen und noch viel mehr. Der Standard wächst regelmäßig, weil neue Zeichen und Emojis hinzukommen.
Das alles verwaltet das Unicode Consortium — eine internationale Non-Profit-Organisation, der unter anderem große Technologieunternehmen wie Apple, Google, Microsoft und IBM angehören.
Unicode und Schriftarten: Was ist eigentlich der Unterschied?
Das ist wohl die häufigste Verwirrung rund um dieses Thema. Viele denken, „Unicode-Schriftart“ bedeutet einfach eine besondere Art von Schriftart. Aber das stimmt nicht ganz.
Lass uns das sauber trennen:
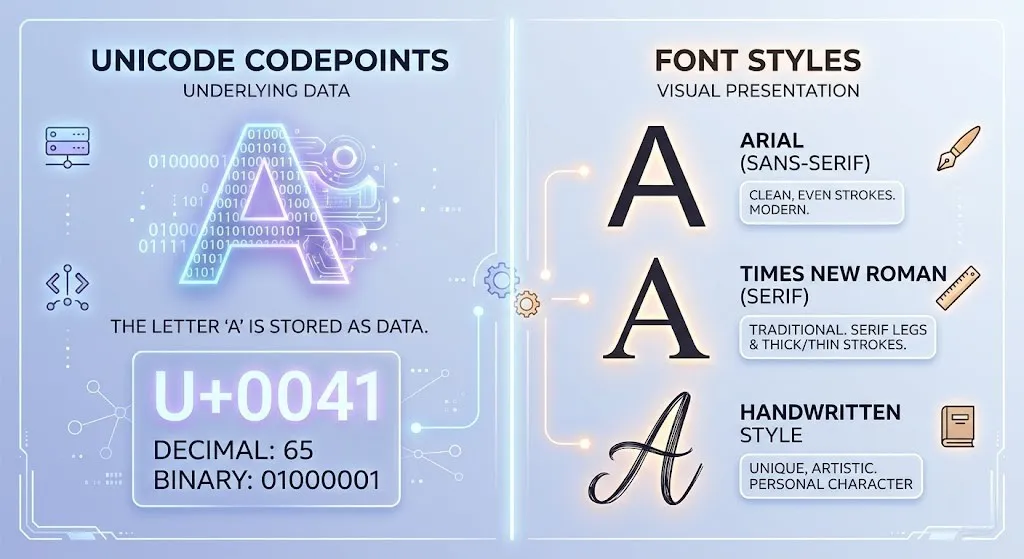
Unicode ist das Nummernsystem. Es sagt: „Das Zeichen ,A‘ hat die Nummer 65″ — oder in der Unicode-Schreibweise: U+0041. Es definiert, was ein Zeichen ist. Nicht, wie es aussieht.
Die Schriftart (Font) ist der Gestalter. Sie nimmt diese Nummer und zeichnet daraus eine sichtbare Form — die sogenannte Glyphe. Arial zeichnet ein anderes „A“ als Times New Roman. Aber beide beziehen sich auf denselben Unicode-Codepoint U+0041.
Ein Vergleich aus dem Alltag: Stell dir eine Hausnummer vor. Die Nummer 17 in deiner Straße ist immer dieselbe Adresse — egal ob das Schild blau oder rot ist, ob die Zahl groß oder klein geschrieben ist. Unicode ist die Adresse. Die Schriftart ist das Schild.
Wenn du in Word oder Google Docs die Schriftart von Arial auf Georgia wechselst, ändert sich ausschließlich das visuelle Erscheinungsbild. Der Unicode-Wert des Buchstabens darunter bleibt zu 100 % gleich. Das ist der Kern des Systems.
Eine sogenannte „Unicode-Schriftart“ ist daher einfach eine Schriftart, die möglichst viele Unicode-Codepoints abdeckt — also möglichst viele Zeichen darstellen kann. Normale Schriftarten decken oft nur ein Schriftsystem ab (zum Beispiel Latein). Unicode-Schriftarten versuchen, viele Schriftsysteme gleichzeitig zu unterstützen.
Die Geschichte: Warum musste Unicode überhaupt kommen?
Um wirklich zu verstehen, warum Unicode so wichtig ist, hilft ein kurzer Blick zurück.
Das ASCII-Problem
In den 1960er Jahren entwickelten amerikanische Ingenieure ASCII — den „American Standard Code for Information Interchange“. Das System war für damalige Verhältnisse gut, hatte aber einen riesigen Nachteil: Es konnte nur 128 Zeichen speichern. Das reichte gerade für englische Groß- und Kleinbuchstaben, die Zahlen 0–9 und ein paar Sonderzeichen wie den Punkt oder das At-Zeichen.
Was fehlte? Alles andere. Deutsche Umlaute (ä, ö, ü), französische Akzentbuchstaben (é, à, ç), arabische Schrift, chinesische Zeichen — komplett unmöglich.
Die Zeit der Insellösungen
Jedes Land bastelte dann eigene Erweiterungen. Westeuropa bekam ISO-8859-1, auch bekannt als „Latin-1″. Japan entwickelte Shift-JIS. Korea hatte EUC-KR. Das Ergebnis: Chaos. Ein Text, der in einem System korrekt gespeichert wurde, sah in einem anderen wie Kauderwelsch aus.
Entwickler, die internationale Software bauten, hatten Albträume. Jede neue Sprache bedeutete neue Kompatibilitätsprobleme.
Unicode als Lösung
1991 erschien Unicode Version 1.0. Die Idee: Statt hundert verschiedener Systeme ein einziges, das alle Schriftsysteme der Welt vereint. Statt 128 oder 256 Zeichen theoretisch über eine Million mögliche Codepoints — weit mehr als genug für alle je existierenden Schriftzeichen der Menschheit.
Die Akzeptanz kam nicht über Nacht. Aber mit der Verbreitung des Internets setzte sich Unicode rasend schnell durch. Heute ist es der Standard — nicht nur eine Option.
Wie Unicode technisch funktioniert – Schritt für Schritt erklärt
Du brauchst dafür kein technisches Vorwissen. Lass uns das in klaren Schritten durchgehen.
Schritt 1: Der Codepoint
Jedes Zeichen in Unicode bekommt eine eindeutige Zahl — den Codepoint. Er wird in der Form U+XXXX geschrieben, wobei XXXX eine hexadezimale Zahl ist.
Ein paar Beispiele:
- U+0041 → A (lateinisches Großes A)
- U+00E4 → ä (a mit Umlaut)
- U+4E2D → 中 (chinesisches Zeichen für „Mitte“)
- U+1F600 → 😀 (lachendes Emoji)
- U+20AC → € (Euro-Zeichen)
Diese Nummern sind fest. Sie ändern sich nie. Das ist der Kern von Unicodes Stärke — absolute Eindeutigkeit.
Schritt 2: Das Encoding (Kodierung)
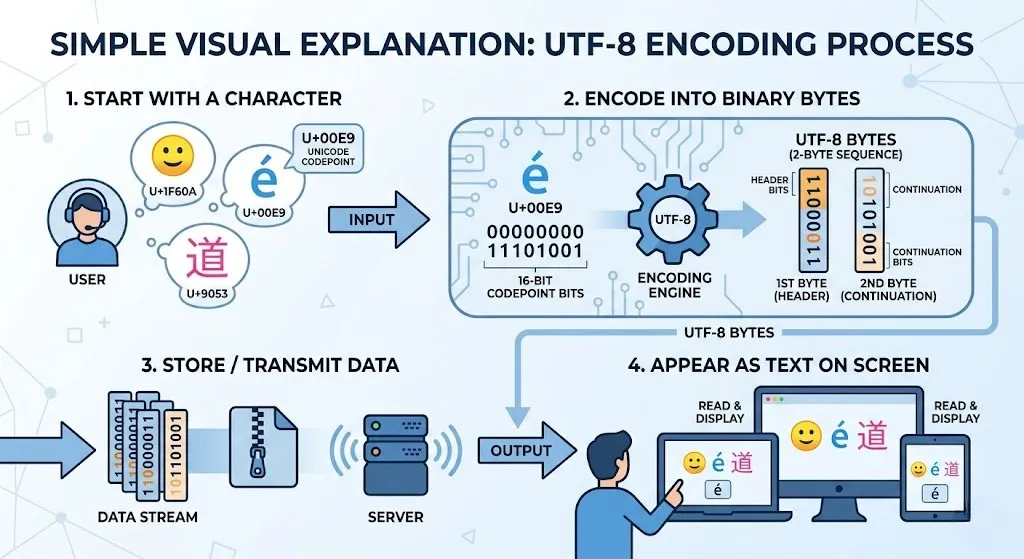
Unicode selbst sagt nur, welche Nummer ein Zeichen hat. Aber wie speichert ein Computer diese Nummer als Einsen und Nullen (Bytes)?
Dafür gibt es verschiedene Kodierungen:
UTF-8 ist heute die bei weitem häufigste. Sie ist clever aufgebaut: Häufige Zeichen wie lateinische Buchstaben brauchen nur ein Byte. Seltenere Zeichen wie chinesische Schriftzeichen brauchen bis zu vier Bytes. Das spart Speicherplatz und ist trotzdem vollständig Unicode-kompatibel. UTF-8 ist auch rückwärtskompatibel mit ASCII — alte ASCII-Texte laufen unter UTF-8 ohne Probleme.
UTF-16 nutzt mindestens zwei Bytes pro Zeichen. Windows und Java verwenden es intern. Es ist praktisch für Sprachen, die viele Zeichen außerhalb des ASCII-Bereichs nutzen, aber verbraucht mehr Speicher für rein englische Texte.
UTF-32 gibt jedem Zeichen immer vier Bytes — egal wie häufig oder selten es ist. Einfach in der Verarbeitung, aber speicherintensiv. Wird selten im Web verwendet.
Im Web hat UTF-8 gewonnen. Wenn du eine Webseite öffnest und im Quellcode <meta charset=“UTF-8″> siehst — das ist Unicode, das still und leise im Hintergrund arbeitet.
Schritt 3: Die Darstellung durch die Schriftart
Erst wenn ein Zeichen auf dem Bildschirm erscheinen soll, kommt die Schriftart ins Spiel. Sie enthält für jeden Codepoint eine fertige Zeichnung — die Glyphe.
Sucht das Betriebssystem zum Beispiel nach der Glyphe für U+00E4 (ä), schaut es in der aktiven Schriftart nach. Findet es sie, zeichnet es das Zeichen. Findet es sie nicht, springt ein Fallback-Mechanismus ein: Das System sucht eine andere installierte Schriftart, die dieses Zeichen kennt. Findet es gar nichts, erscheint ein kleines Kästchen (□) — das sogenannte „Tofu“.
Schritt 4: Eingabe und Verarbeitung
Wenn du auf deiner Tastatur „A“ tippst, erzeugt das Betriebssystem intern den Unicode-Codepoint U+0041. Dieser Wert wird in die Anwendung weitergegeben, dort verarbeitet, gespeichert und schließlich auf dem Bildschirm als Glyphe dargestellt. Alles passiert in Millisekunden, völlig unsichtbar für dich.
Was sind Unicode-Schriftarten? Und welche gibt es?
Der Begriff „Unicode-Schriftart“ wird oft missverständlich verwendet. Technisch gesehen ist jede moderne Schriftart eine Unicode-Schriftart, weil alle modernen Fonts intern mit Unicode-Codepoints arbeiten.
Was man eigentlich meint, wenn man von einer „echten Unicode-Schriftart“ spricht: eine Schriftart, die möglichst viele der über 140.000 Unicode-Codepoints abdeckt — also viele Sprachen und Schriftsysteme gleichzeitig unterstützt.
Bekannte Unicode-Schriftarten mit breiter Abdeckung:
Noto (Google): Noto ist das wohl ehrgeizigste Font-Projekt der Welt. Der Name steht für „No Tofu“ — kein Kästchen, weil für jedes Zeichen eine Glyphe existiert. Google entwickelt Noto als freie Schriftfamilie, die alle existierenden Unicode-Schriftsysteme abdecken soll. Für viele Systeme ist Noto die erste Wahl als universelle Fallback-Schriftart.
DejaVu: Eine freie Schriftart, die auf Bitstream Vera basiert und besonders viele lateinische und griechische Zeichen abdeckt. Verbreitet in Linux-Systemen.
GNU Unifont: Eine Bitmap-Schriftart, die tatsächlich alle (I believe — bitte beim Unicode Consortium verifizieren) aktuellen Unicode-Codepoints abdeckt. Nicht schön für Fließtext, aber enorm als Referenz.
Arial Unicode MS: Microsofts Version mit sehr breiter Zeichenabdeckung. War lange Standard in Office-Produkten.
Code2000: Eine frühe, weit verbreitete Schriftart mit Tausenden von Unicode-Zeichen. Heute weniger relevant, aber historisch wichtig.
Keine dieser Schriftarten deckt alle Unicode-Zeichen ab — das wäre auch ein technisch extrem aufwändiges Projekt. Schriftgestaltung kostet Zeit, und eine gute Glyphe für ein chinesisches Zeichen zu entwerfen ist andere Arbeit als ein lateinisches „a“.
Unicode im Alltag – Konkrete Beispiele, die du kennst

Unicode ist kein abstraktes Konzept. Du begegnest ihm jeden Tag, oft ohne es zu wissen.
Emojis auf verschiedenen Geräten
Das 😂-Emoji hat den Codepoint U+1F602. Ob du es auf einem iPhone, einem Android-Gerät oder im Firefox-Browser siehst — der Codepoint ist immer gleich. Was sich unterscheidet: Apple hat seine eigene Emoji-Schriftart (Apple Color Emoji), Google hat Noto Color Emoji, Microsoft hat Segoe UI Emoji. Deshalb sieht 😂 auf Apple etwas anders aus als auf Android — aber beide meinen dasselbe Zeichen.
Mehrsprachige Websites
Eine internationale Website zeigt gleichzeitig Englisch, Arabisch (von rechts nach links), Japanisch und Chinesisch. Das funktioniert nur, weil alle diese Schriftsysteme in Unicode kodiert sind und ein moderner Browser alle davon darstellen kann — sofern passende Schriftarten installiert sind oder per Web Font geladen werden.
Formular-Eingaben in Apps
Wenn du deinen Namen „Müller“ in ein Online-Formular eingibst, speichert die Datenbank das als Unicode-Codepoints: M-ü-l-l-e-r. Das ü hat den Codepoint U+00FC. Ohne Unicode würde die Datenbank nicht wissen, was mit diesem Sonderzeichen zu tun ist — und der Name würde als unlesbarer Code gespeichert.
Sonderzeichen in Social-Media-Bios
Hast du schon mal Instagram-Profile gesehen, deren Text in einer „anderen Schriftart“ aussah — kursiv, fett oder in Schreibschrift — obwohl Instagram gar keine Schriftartauswahl anbietet? Dahinter stecken Unicode-Zeichen aus mathematischen Zeichensätzen (Mathematical Alphanumeric Symbols, U+1D400 ff.). Diese Zeichen sehen aus wie Buchstaben in verschiedenen Schriftstilen, sind aber tatsächlich eigene Unicode-Zeichen. Ein Trick — kein Font.
URLs mit Umlauten
Wenn du www.example.de/über-uns in deinen Browser tippst, wandelt der Browser das intern in www.example.de/%C3%BCber-uns um. %C3%BC ist die UTF-8-Byte-Sequenz für „ü“. Das passiert automatisch und transparent — dank Unicode.
Programmierer und Unicode
In modernen Programmiersprachen wie Python 3, JavaScript oder Java sind alle Strings intern als Unicode gespeichert. Du kannst Texte in jeder Sprache verarbeiten, ohne dir Gedanken über Kodierungsprobleme machen zu müssen — solange du UTF-8 verwendest.
Unicode und Schriftsysteme der Welt
Ein besonders faszinierender Aspekt von Unicode ist, wie er mit grundlegend verschiedenen Schriftsystemen umgeht.
Schriftsysteme funktionieren sehr unterschiedlich:
Alphabete (wie Latein, Kyrillisch, Griechisch) haben einzelne Buchstaben, die Laute darstellen. Das kennen wir aus dem Deutschen.
Abdschads (wie Arabisch, Hebräisch) schreiben hauptsächlich Konsonanten. Vokale werden oft weggelassen oder als kleine Zeichen über oder unter den Buchstaben geschrieben.
Abugidas (wie Devanagari für Hindi oder Thai) kombinieren Konsonanten mit Vokalzeichen zu Silbeneinheiten.
Silbenschriften (wie japanische Hiragana und Katakana) haben ein Zeichen pro Silbe.
Logografien (wie chinesische Schrift oder Kanji) haben ein Zeichen pro Wort oder Konzept.
All diese fundamental verschiedenen Systeme müssen in Unicode koexistieren — und das tun sie. Unicode hat spezielle Bereiche (sogenannte Blöcke) für jedes Schriftsystem. Der Lateinische Block liegt bei U+0000 bis U+007F. Arabisch bei U+0600 bis U+06FF. Chinesische, japanische und koreanische Zeichen (CJK) nehmen riesige Bereiche zwischen U+4E00 und U+9FFF und noch weiter darüber hinaus ein.
Auch Schriftsysteme, die kaum noch jemand verwendet, sind in Unicode vertreten: Altägyptische Hieroglyphen, Keilschrift aus Mesopotamien, Lineares B aus der minoischen Kultur. Unicode ist nicht nur ein technischer Standard — er ist auch ein Archiv menschlicher Schriftgeschichte.
Unicode für Websites und SEO – Was Websitebetreiber wissen müssen
Wenn du eine Website betreibst oder baust, ist Unicode kein optionales Extra. Es ist Grundlage. Hier sind die wichtigsten Punkte:
Die Charset-Angabe im HTML
Jede Webseite sollte im <head> folgendes stehen haben:
html
<meta charset=“UTF-8″>
Dieses kleine Tag sagt dem Browser und Suchmaschinen-Crawlern: „Lies den Inhalt dieser Seite als UTF-8.“ Ohne diese Angabe kann der Browser raten — und falsch raten. Das Ergebnis sind kaputte Sonderzeichen oder unlesbarer Text.
Google empfiehlt UTF-8 ausdrücklich. Fehlende oder falsche Charset-Angaben können dazu führen, dass Inhalte falsch indexiert werden — ein direkter SEO-Nachteil.
Sonderzeichen in Meta-Descriptions
Zeichen wie ✓, →, ★, ✔ oder • aus dem Unicode-Zeichensatz können in Meta-Descriptions und Seitentiteln die Klickrate in Suchergebnissen verbessern. Sie fallen auf, weil die meisten Snippets rein textuell sind.
Wichtig: Diese Zeichen funktionieren nur zuverlässig, wenn die Seite korrekt als UTF-8 kodiert ist. Sonst erscheinen sie als „?“ oder Kästchen im Suchergebnis — das Gegenteil des gewünschten Effekts.
URLs und Umlaute
Deutsche URLs mit Umlauten sind technisch möglich (IDN — Internationalized Domain Names). Aber intern werden Umlaute in URLs als Prozent-kodierte UTF-8-Sequenzen übertragen. Das sollte dein Webserver und dein CMS automatisch korrekt handhaben. Falls nicht, entstehen kaputte Links — und kaputte Links sind schlecht für SEO und Nutzererfahrung.
Die empfohlene Praxis: Verwende in URLs nach Möglichkeit keine Umlaute. Statt /über-uns lieber /ueber-uns oder /about. Das vermeidet technische Probleme auf älteren Systemen.
Mehrsprachige Websites (hreflang)
Wenn du Inhalte in mehreren Sprachen anbietest, verwendest du hreflang-Tags, um Google zu sagen, welche Version für welche Sprache und Region gedacht ist. Dahinter steckt ebenfalls Unicode: Die Sprachcodes (de, ja, ar, zh) und Ländercodes (DE, JP, SA, CN) sind als ASCII/UTF-8 Strings kodiert.
Wichtiger als der technische Aspekt: Dein Content in anderen Sprachen muss korrekt als UTF-8 gespeichert sein. Arabischer oder chinesischer Text, der falsch kodiert wurde, kann von Google nicht korrekt gelesen werden.
Schriftarten im Web (Web Fonts)
Wenn du eine Google Font oder eine andere Web Font lädst, lädst du eigentlich eine Datei, die Unicode-Codepoints auf Glyphen abbildet. Moderne Web-Font-Formate wie WOFF2 sind optimiert und unterstützen Unicode.
Ein häufiges Problem: Deine Web Font unterstützt nur lateinische Zeichen. Wenn ein Nutzer deiner Website deinen Text in einer anderen Schrift sieht (weil seine Systemsprache anders ist), greift der Browser auf eine Fallback-Schriftart zurück — und die sieht oft anders aus als gewünscht. Die Lösung: Font-Subsets gezielt auswählen oder eine Schriftart mit breiter Unicode-Abdeckung verwenden.
Unicode in der Praxis für Entwickler
Wenn du Websites oder Apps baust, begegnest du Unicode täglich. Hier ein paar praktische Punkte:
Datenbankenkodierung
MySQL, PostgreSQL und andere Datenbanken müssen explizit für UTF-8 konfiguriert werden. In MySQL gibt es sogar einen Unterschied zwischen utf8 (das eigentlich nur 3-Byte-Unicode unterstützt und Emojis nicht korrekt speichern kann) und utf8mb4 (das echtes 4-Byte-UTF-8 unterstützt). Wenn deine Datenbank Emojis nicht speichern kann, liegt es meist an dieser falschen Einstellung.
Die Empfehlung: Immer utf8mb4 in MySQL verwenden. Es gibt keinen Nachteil.
String-Verarbeitung in Programmiersprachen
In Python 3 sind alle Strings standardmäßig Unicode. In Python 2 war das noch nicht so — was zu endlosen Encoding-Fehlern führte. Beim Lesen von Dateien sollte man in Python immer encoding=’utf-8′ angeben:
python
with open(‚datei.txt‘, ‚r‘, encoding=’utf-8′) as f:
inhalt = f.read()
In JavaScript sind Strings intern UTF-16 kodiert. Das bedeutet, dass Zeichen außerhalb der BMP (Basic Multilingual Plane) — wie viele Emojis — technisch aus zwei Code Units bestehen. Das kann bei der Berechnung von String-Längen zu unerwarteten Ergebnissen führen.
JSON und Unicode
JSON-Dateien sollten immer als UTF-8 gespeichert werden. Der JSON-Standard schreibt das sogar vor. Sonderzeichen können in JSON zusätzlich als Unicode-Escape-Sequenzen geschrieben werden: \u00E4 für ä. Das ist besonders nützlich, wenn du sicherstellen willst, dass kein System die Kodierung falsch interpretiert.
Häufige Fragen zu Unicode – AEO-optimiert
Was ist Unicode einfach erklärt?
Unicode ist ein weltweiter Nummerierungsstandard für Schriftzeichen. Jedes Zeichen — egal ob Buchstabe, Zahl, Sonderzeichen oder Emoji — bekommt eine einmalige Nummer (Codepoint). So kann jeder Computer auf der Welt dieselben Zeichen eindeutig erkennen und korrekt anzeigen.
Was versteht man unter einer Unicode-Schriftart?
Eine Unicode-Schriftart ist eine Schriftdatei, die viele Unicode-Codepoints abdeckt — also viele verschiedene Zeichen und Schriftsysteme darstellen kann. Alle modernen Schriftarten verwenden Unicode intern, aber manche decken mehr Zeichen ab als andere.
Was ist der Unterschied zwischen Unicode und ASCII?
ASCII ist ein älteres System aus den 1960ern und kann nur 128 Zeichen verarbeiten — hauptsächlich englische Buchstaben und Zahlen. Unicode unterstützt über 140.000 Zeichen aus allen Schriftsystemen der Welt. ASCII ist im Grunde eine sehr kleine Untermenge von Unicode.
Was ist UTF-8 und warum wird es im Web verwendet?
UTF-8 ist eine Methode, Unicode-Codepoints als Bytes zu speichern. Es ist platzsparend, da häufige Zeichen weniger Bytes brauchen. Es ist rückwärtskompatibel mit ASCII. Und es funktioniert auf praktisch allen Systemen. Deshalb ist es der Standard für Websites, APIs und Dateien im Web. (Ich glaube, es liegt bei über 95–98 % aller Websites — diese Zahl solltest du bei W3Techs aktuell verifizieren.)
Was passiert, wenn eine Schriftart ein Unicode-Zeichen nicht enthält?
Das Betriebssystem sucht automatisch nach einer anderen installierten Schriftart, die das Zeichen kennt. Findet es keine, zeigt es ein Platzhalterfeld (□) oder ein Fragezeichen. Dieses Kästchen nennt man unter Entwicklern liebevoll „Tofu“.
Kann ich Unicode-Zeichen in Überschriften und Texten verwenden?
Ja, vollständig. Alle modernen Browser, Betriebssysteme und Textverarbeitungsprogramme unterstützen Unicode. Du kannst Symbole (←, →, ✓, ★), Emojis oder Zeichen aus anderen Sprachen direkt in Texte einfügen — solange die Seite als UTF-8 kodiert ist.
Wie kann ich Unicode-Zeichen auf meinem Computer eingeben?
Es gibt mehrere Wege: Über Zeichentabellen (Windows: Zeichentabelle-App, Mac: Sonderzeichen-Palette), über HTML-Entities (z. B. € für €), über Tastaturkürzel oder direkte Eingabe des Codepoints. In manchen Programmen kannst du auch einfach den Codepoint eintippen und dann eine bestimmte Taste drücken, um ihn in das Zeichen umzuwandeln.
Unicode und Typografie – Was Gestalter wissen sollten
Für Designer und Typografen hat Unicode direkte Auswirkungen auf die Arbeit.
Ligaturen und OpenType
OpenType-Schriftarten können über Unicode hinaus spezielle typografische Funktionen anbieten — sogenannte Features. Dazu gehören Ligaturen (fi, fl), Swashes, alternative Glyphen oder Kapitälchen. Diese Features werden nicht durch eigene Unicode-Codepoints definiert, sondern durch spezielle Anweisungen in der Schriftdatei. CSS und InDesign können diese Features aktivieren.
Laufrichtung (Bidirektionaler Text)
Unicode definiert auch, wie Text angezeigt werden soll, wenn links-nach-rechts und rechts-nach-links Schriften gemischt werden. Der sogenannte Bidi-Algorithmus (Unicode Bidirectional Algorithm) legt fest, in welche Richtung jeder Teil des Textes läuft. Das ist besonders wichtig für Websites, die Arabisch oder Hebräisch zusammen mit Englisch anzeigen.
Kerning und Abstände
Die Schriftart bestimmt das Kerning (Abstände zwischen bestimmten Buchstabenpaaren) und den allgemeinen Zeichenabstand. Unicode sagt dazu nichts. Das ist komplett Aufgabe des Fonts und des Rendering-Systems.
Schrift-Stacking im Web
In CSS gibt es die font-family-Eigenschaft, die mehrere Schriftarten als Fallback-Liste erlaubt:
css
font-family: ‚Meine Schrift‘, ‚Noto Sans‘, sans-serif;
Das ist im Grunde dasselbe Fallback-Prinzip wie bei Unicode: Zuerst wird die Hauptschrift versucht. Fehlt eine Glyphe, springt die nächste Schrift ein. Das funktioniert nahtlos — und dahinter stecken Unicode-Codepoints.
Zusammenfassung: Das Wichtigste auf einen Blick
Unicode ist keine komplizierte Sache. Es ist eigentlich ein ganz einfaches Konzept: Jedem Zeichen der Welt eine eindeutige Nummer geben. Diese Nummer gilt überall — auf jedem Gerät, in jedem Land, in jeder Sprache.
Schriftarten sind die Gestalter dieser Nummern. Sie entscheiden, wie ein Zeichen aussieht. Mehr nicht.
Zusammengefasst:
- Unicode = das Nummerierungssystem für alle Zeichen der Welt
- Codepoint = die eindeutige Nummer eines Zeichens (z. B. U+0041 für A)
- Encoding (UTF-8, UTF-16) = die Methode, diese Nummern als Bytes zu speichern
- Schriftart (Font) = die visuelle Darstellung eines Codepoints als Glyphe
- Unicode-Schriftart = eine Schriftart, die viele Codepoints aus vielen Schriftsystemen abdeckt
- Für Websites gilt: Immer <meta charset=“UTF-8″> im HTML, Datenbank auf UTF-8/utf8mb4 setzen, URL-Sonderzeichen richtig kodieren
Ohne Unicode wäre das moderne Internet nicht möglich. Jedes Mal, wenn du eine arabische Nachricht auf deinem deutschen Smartphone liest, ein japanisches Emoji verschickst oder einen internationalen Artikel abrufst — Unicode arbeitet im Hintergrund still und zuverlässig.
Weiterführende Ressourcen
Wenn du tiefer einsteigen möchtest, empfehle ich folgende Anlaufstellen (ich kann keine direkte Verlinkung mit Garantie auf aktuelle URLs geben, aber diese Quellen sind real und verifizierbar):
- unicode.org — Die offizielle Website des Unicode Consortiums. Dort findest du den vollständigen Standard, Zeichentabellen und alle aktuellen Codepoints.
- Wikipedia: Unicode — Guter Überblick auf Deutsch, mit historischen Hintergründen und technischen Details.
- W3Techs — Aktuelle Statistiken zur Verbreitung von UTF-8 im Web.
- IONOS Digital Guide — Deutsche Erklärung mit praktischen Anwendungsbeispielen.
Typolexikon — Für die typografische Perspektive auf Unicode und Schriftdateien.